LLM Application
RAG chatbot for company knowledge bases
Upload internal documents and ask questions in plain English. Answers stream back in seconds with expandable source citations pinned to the exact page.

Live demo — RAG Knowledge Base querying Meridian Technologies documents with page-level source citations.
Problem
Internal knowledge is trapped in PDFs — policy handbooks, IT guides, financial reports, onboarding documents. Finding a specific answer means opening five files, scanning headers, and hoping the right section is where you expect it. The system lets teams upload any PDF corpus and query it conversationally. Every answer cites the exact source document and page number it was drawn from. If the retrieved context does not meet a minimum similarity threshold the system refuses to answer rather than hallucinate. This is a critical behaviour for enterprise use where a wrong answer is worse than no answer.
Architecture
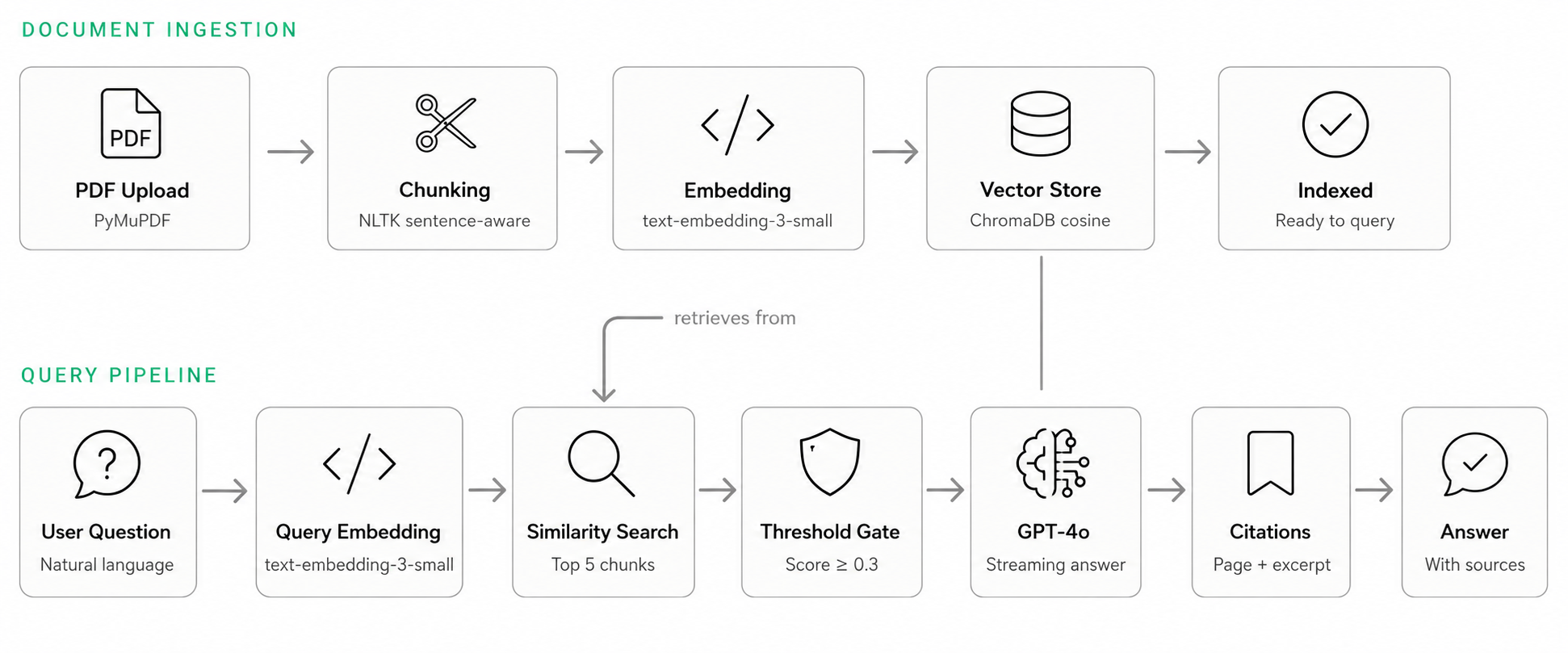
MetricsOperational parameters from deployed configuration. Retrieval accuracy benchmarking with Ragas is planned for the production release.
Similarity threshold
0.3
Chunks retrieved per query
Top 5
Chunk size
800 chars
Embedding model
text-embedding-3-small
Tech stack
Production considerations
- Hallucination guard — The system checks whether the best retrieved chunk meets a minimum similarity threshold before calling the LLM at all. Below threshold it returns a canned refusal rather than generating a plausible but unsupported answer.
- Citations decoupled from LLM output — Source citations are the actual retrieved chunks from the vector store, not references extracted from the LLM response. This makes citations deterministic and auditable regardless of how the model phrases its answer.
- Document-scoped search — Queries can be scoped to a single document via an optional doc_id filter on the vector search, letting users interrogate one file without cross-contamination from the rest of the corpus.
- Stateless queries — Each query is independent with no conversation history sent to the LLM. This keeps costs predictable and latency low, but means follow-up questions cannot reference prior answers without client-side history injection.
- PDF ingestion only — The current pipeline handles PDF documents. Extending to DOCX, HTML, and plain text is straightforward and available per client requirements.
- Authentication and access control — All endpoints are currently open for demo purposes. Production deployment adds per-user authentication, document-level RBAC, and audit logging for compliance.
Explore this project
Live demo and source code links will be added as they become available.