Document Automation
Invoice OCR and document automation
From PDF to validated JSON in under 3 seconds: vendor, line items, totals, and due dates extracted and ready for your ERP or accounting system.
Problem
Accounts payable teams spend 3–8 minutes manually keying each invoice into their ERP. At 200 invoices a month that is over 25 hours of error-prone data entry. One transposition mistake on a total or due date can cascade into payment disputes and reconciliation work that takes far longer to unwind. The system ingests invoice PDFs from any source: email attachment, scanned upload, or API push, and returns validated structured JSON in under 3 seconds. No templates. No per-vendor configuration. Works on scanned images, digital PDFs, and mixed-quality documents.
System demo
Inference running on SKU-110K public dataset · YOLOv8m pretrained checkpoint · Annotations rendered with OpenCV
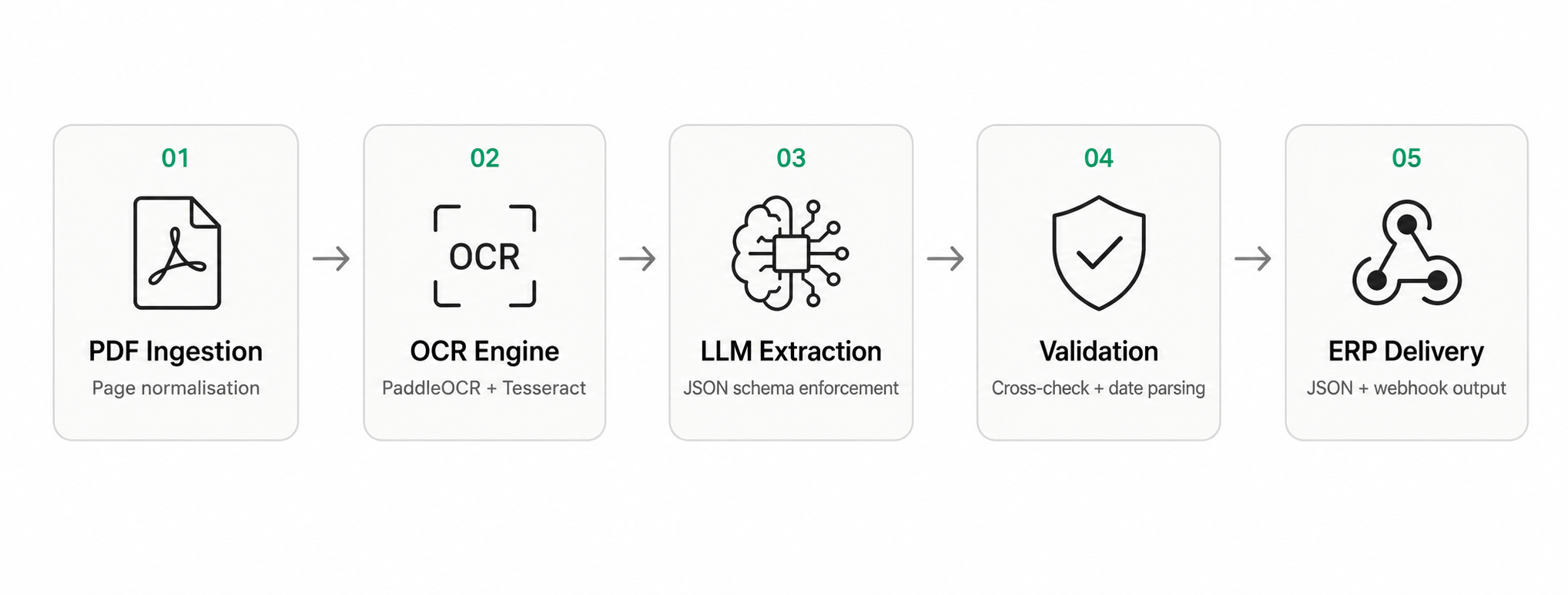
Architecture
MetricsBenchmarked on SROIE public dataset. Results reflect prototype performance — production accuracy improves with domain-specific fine-tuning.
Field extraction accuracy
94.2%
Avg processing time
2.8s
Structured fields extracted
12
Documents in benchmark
500
Tech stack
Production considerations
- Document variability — Invoices have no standard layout. The pipeline handles multi-column, multi-page, and rotated documents without per-vendor templates.
- Validation logic — Extracted line item subtotals are cross-checked against the stated total. Mismatches are flagged for human review rather than silently passed downstream.
- Scanned document quality — Low-resolution or skewed scans degrade OCR accuracy. The pipeline applies deskewing and contrast normalisation before OCR to recover legibility.
- Data residency — Invoice data contains supplier details and financial figures. The pipeline can run fully on-premises with a local LLM to satisfy data residency requirements.
- ERP integration — Output JSON schema is configurable per client. Native connectors available for QuickBooks, Xero, and SAP via webhook or direct API.
Explore this project
Live demo and source code links will be added as they become available.